Latent Diffusion
영어로 다 바꾸기 너무 귀찮아서... 달파 입사 전에 해야 할 것들이 많으므로 Latent Diffusion은 원문 그대로 복붙.
1. Introduction
- The research area covered by the paper
- Image generation
- Auto encoder + Diffusion
- Conditional model (sampling + other info. about an image)
- Limitations of previous studies in this task
- Diffusion Model(DM)은 pixel 단위의 noise 추가 및 제거 → 연산량이 너무 많다!
- 연산량을 줄이면서 DM의 생성 능력은 유지할 수 있을까?
- 학습 시 초기 이미지 데이터 x를 latent space로 축소시킨 다음, DM process를 거쳐보자!
- Contributions
- Auto Encoder → Latent Representation + Diffusion process 구조 제시
- Latent Representation으로 noising/denoising을 통한 Efficiency of the Computational Cost
- 본인들이 제안한 Latent DM에 Condition(Guidance)를 제공하도록 U-Net에 Cross-Attention 구조 제시
2. Related Work
DDPM
- Latent DM의 denoising U-net 구조 설계 및 제안
Auto Encoder
- original represenation을 더 낮은 차원의 latent로 축소시켜 유의미한 feature 학습
- 이를 기반으로 VAE(Variational Auto Encoder)라는 이미지 생성 모델 존재
- Encoding 시 a standard normal distribution의 variational value를 통해 latent space를 standard normal distribution으로 근사
- 이 과정에서 Bayesian background를 통해 ELBO(Evidence Loss Bound)를 제시 → 원본 이미지 분포를 몰라도 간접적으로 denoising의 sampling distribution 차이를 계산하는 KL-Divergence을 통해 학습
GAN
- Adversarial architecture를 통해 이미지 생성
- Generator가 Discriminator를 압도하면 학습 종료
3. Methodology
Main Idea
- DDPM + latent space architecture
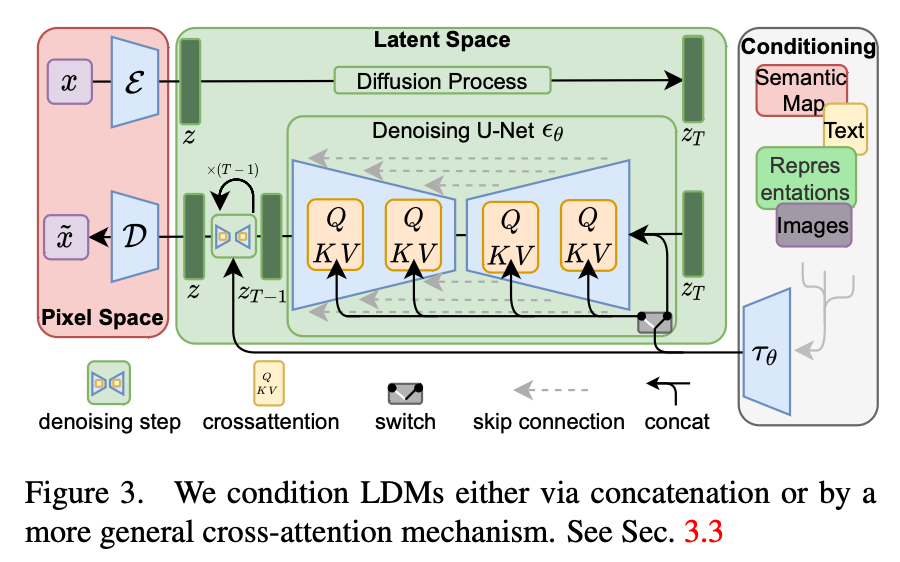
- 이미지를 AutoEncoder로 압축한 뒤, Latent representation을 noise 추가/제거해보자!
- Auto Encoder를 통해 원본 이미지에서 latent representation을 얻고, 해당 space에서 noise 추가/제거 과정을 학습하기 → 이후 sampling 또한 latent space에서 시행
- Condition(Guidance)를 Cross-Attention으로 제시하여 학습 및 이미지 생성 도움
→ Computational Cost를 줄이면서 동시에 이미지 품질 손상을 막거나 되려 더 올려보자!
-
Training loss
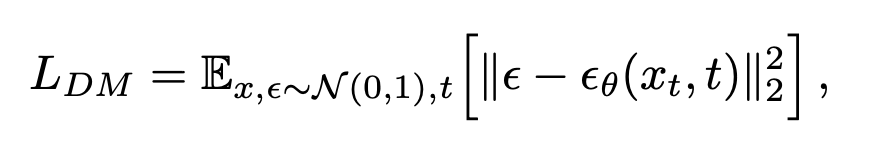 기존 loss에서
기존 loss에서
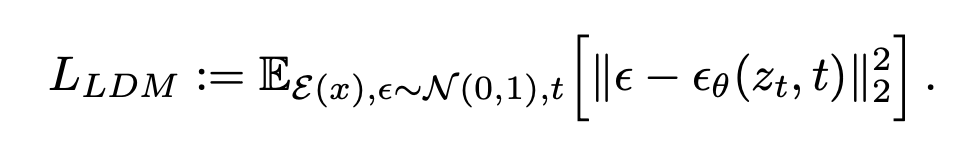 로 noise의 distribution을 latent space로 변경만 한 꼴
로 noise의 distribution을 latent space로 변경만 한 꼴 -
Conditional loss
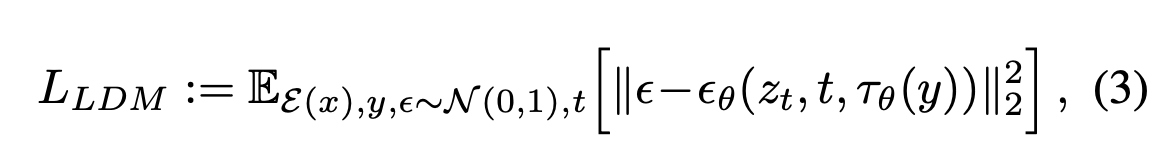
-
τθ(y): Domain specific embedding by τθ → condition y를 latent
-
ϕi(zt): intermediate representation of the UNet implementing ϵθ → noise의 중간 embedding
Contributions
- Latent DM은 Computational cost 면에서 매우 효율적! (noise 추가, 제거 시 훨씬 낮은 차원에서 이루어지므로…)
- (본문 내용) training the most powerful DMs often takes hundreds of GPU days (e.g. 150 - 1000 V100 days in)
- (본문 내용) producing 50k samples takes approximately 5 days on a single A100 GPU
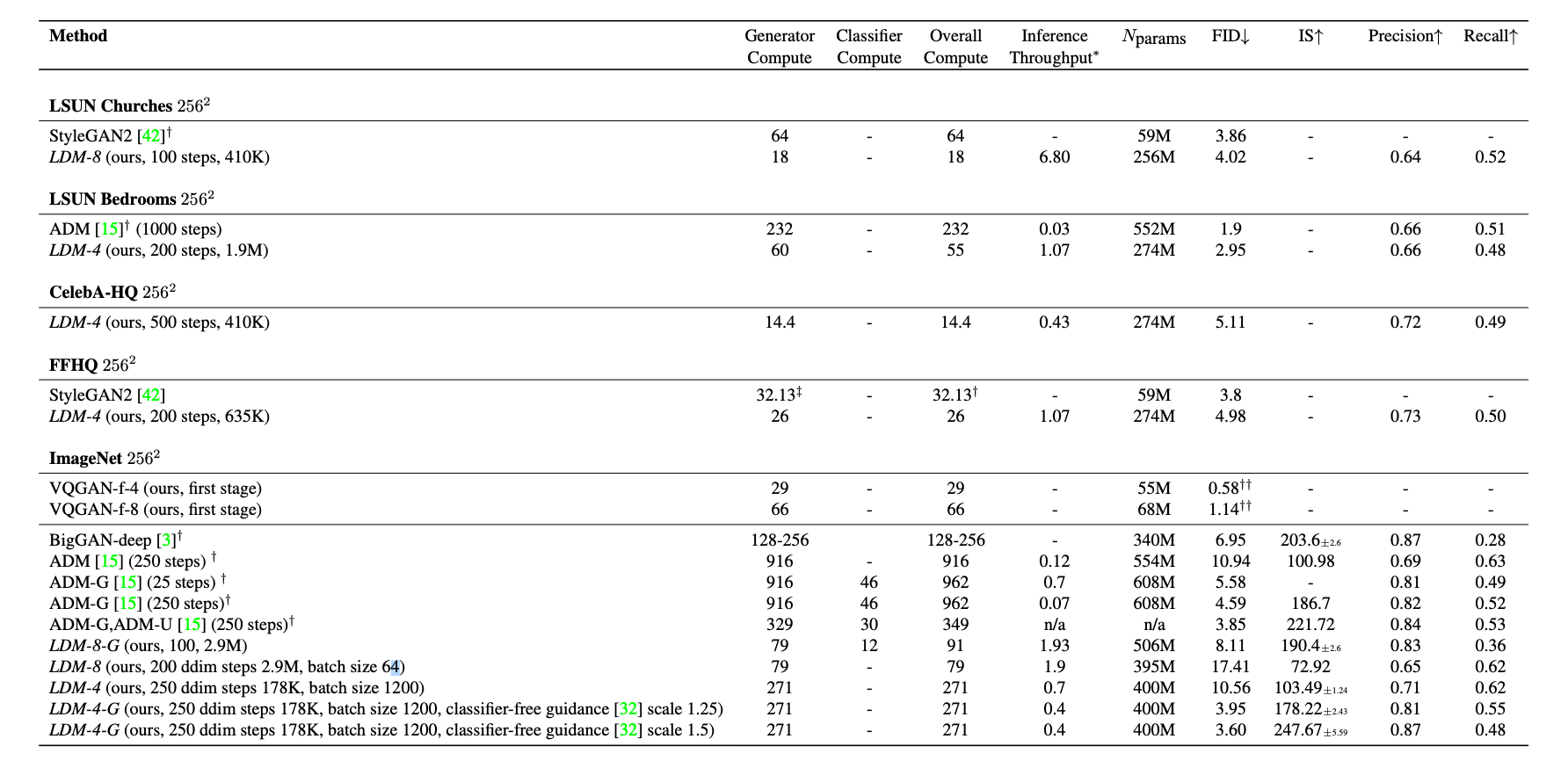
- LDM-4-G의 경우 inference Throughput (Samples/sec)이 0.4로 LDM 중 가장 무거움. 그런데 본문 내용대로 단순 계산하면 DDPM 기반 모델일 경우 0.116으로 약 3.7배 차이!
- latent space 외에도 Text, Image, Class 등 Condition을 받아 Cross-attention 구조로 이미지 생성 품질을 높임
- (바로 위 장표의 LDM-O-G 에서 G가 Guidance(condition)을 지칭
- FID가 매우 낮고 IS는 매우 높음을 알 수 있음
4. Experiments and Results
Model architecture
Factor: the compression ratio of the latent representation
KL: Indicates that the model does not use the VQ method to compress a latent representation.
G: Guidance, which is equivalent to a condition. They use a BERT tokenizer and a transformer to infer a latent code.
Datasets
CelebA-HQ: A celebrity face image dataset
FFHQ(Flickr-Faces-HQ): A normal face image dataset
LSUN-Churches: church images
LSUN-Bedrooms: bedroom images
ImageNet
Baseline
w/o condition
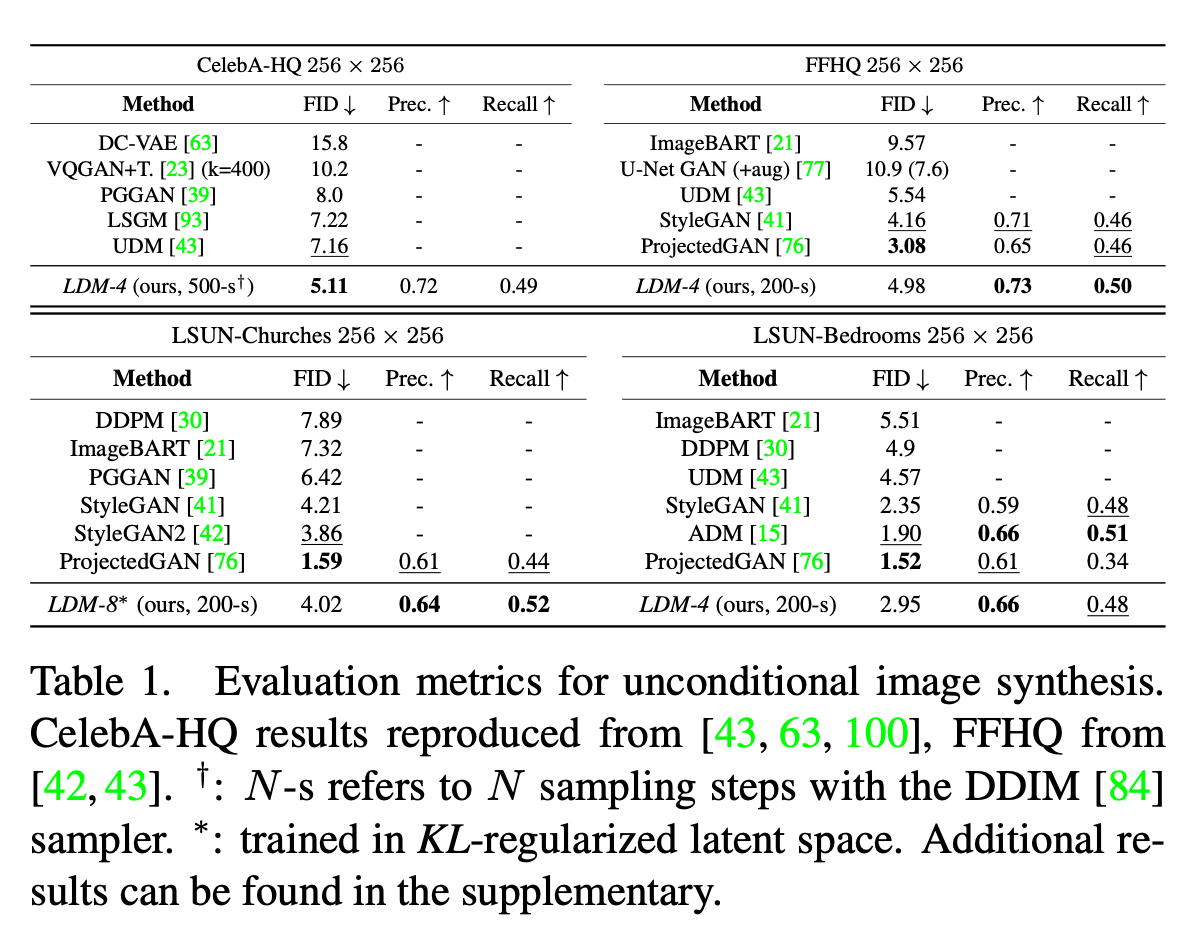
Summary table
| Model | Type | Key Idea/Role |
|---|---|---|
| DC-VAE | VAE | Deep conv. VAE for image synthesis |
| VQGAN+T | Hybrid | VQGAN + Transformer for text/image generation |
| PGGAN | GAN | Progressive training for high-res images |
| LSGM | Diffusion | Latent space score-based diffusion |
| UDM | Diffusion | Unified framework for diffusion models |
| ImageBART | Transformer | BART for image token sequence generation |
| U-Net GAN | GAN | U-Net generator for detail preservation |
| StyleGAN | GAN | Style-based control over image features |
| ProjectedGAN | GAN | Discriminator on projected features |
w text-condition
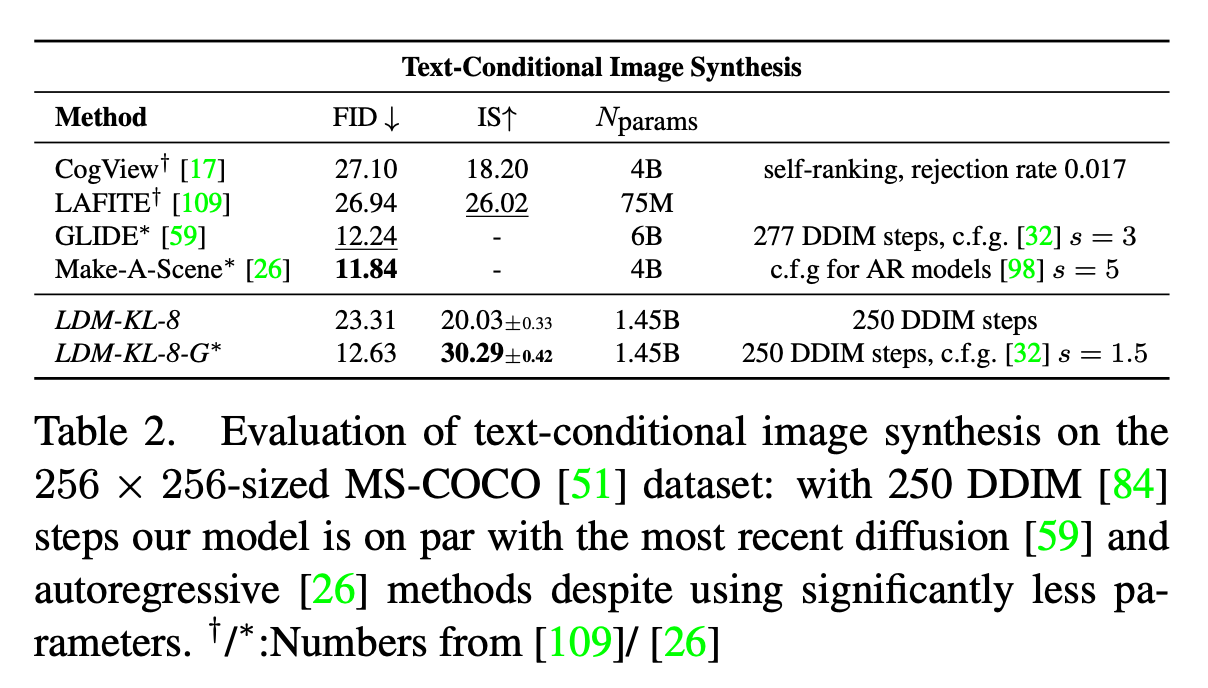
Summary table
| Model | Type | Key Idea/Role | Application |
|---|---|---|---|
| CogView | Transformer | Text-to-image via image token transformer | Text-to-image (Chinese) |
| LAFITE | GAN | Text-to-image without explicit text supervision | Zero-shot text-to-image |
| GLIDE | Diffusion | Text-guided diffusion, classifier-free guidance | High-quality text-to-image |
| Make-A-Scene | Diffusion | Text + layout for compositional generation | Scene-aware image synthesis |
w class-condition
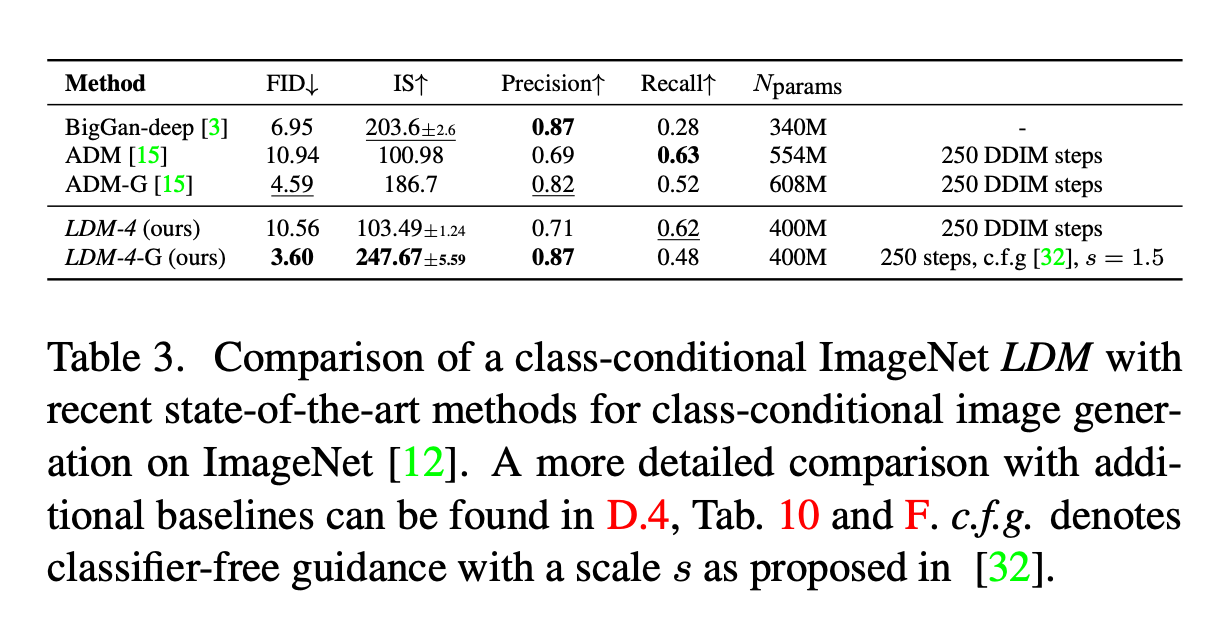
Summary Table
| Model | Type | Key Feature |
|---|---|---|
| BigGAN-deep | GAN | Deep, class-conditional |
| ADM | Diffusion | Class-conditional denoising |
| ADM-G | Diffusion | Classifier-guided denoising |
Inpainting
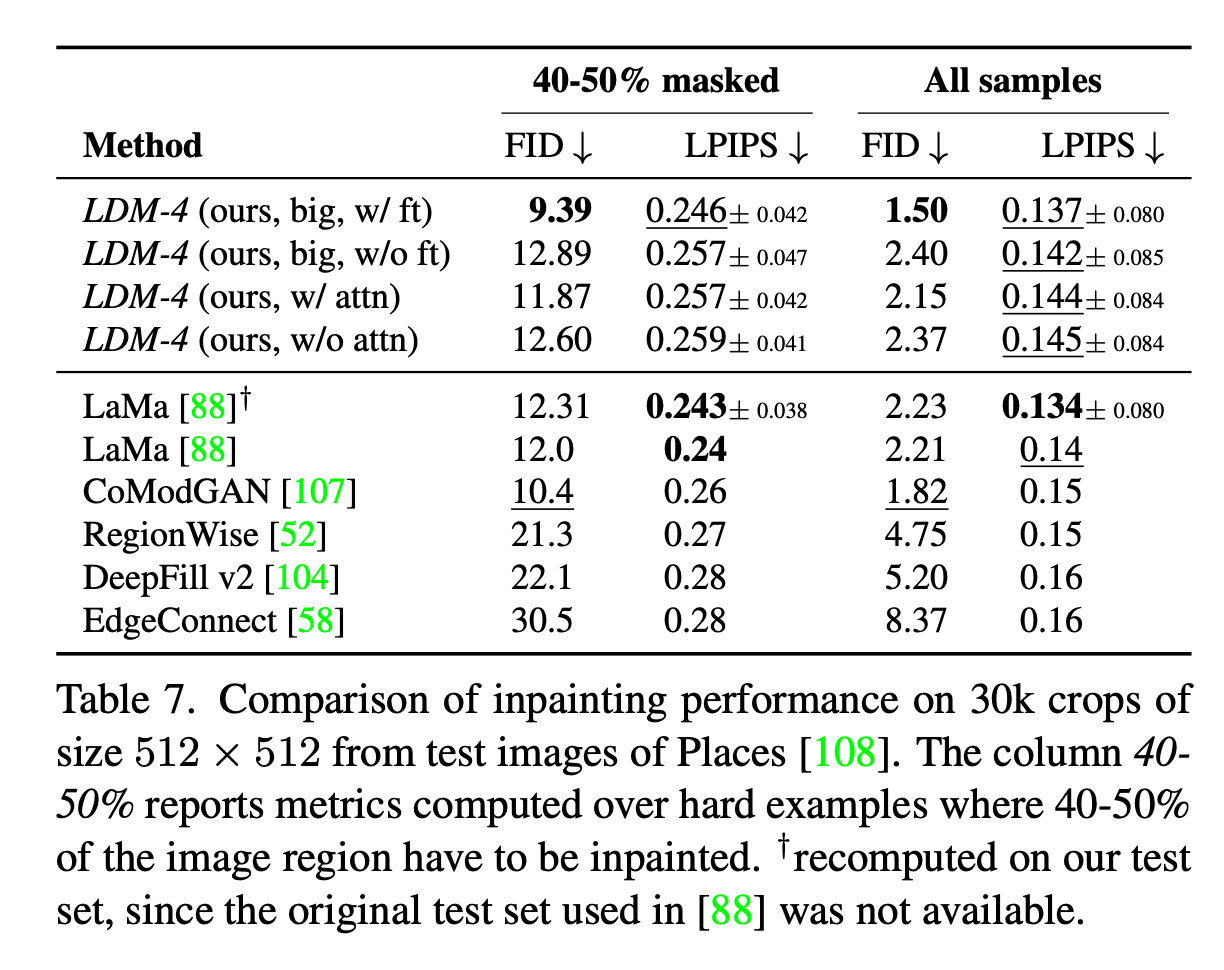
Summary Table
| Model | Type | Key Feature/Idea |
|---|---|---|
| LaMa | CNN (FFC-based) | Fourier Convolutions, large masks |
| CoModGAN | GAN | Contextual modulation |
| RegionWise | CNN | Region-wise normalization/attention |
| DeepFillv2 | GAN (Gated Conv) | Gated conv, contextual attention |
| EdgeConnect | Two-stage (Edge + GAN) | Edge prediction + inpainting |
결과
Already, LDMs show the performances mentioned above, achieving SOTA results on the CelebA-HQ 256x256 dataset. Therefore, the text-conditional image synthesis model achieved better FID and IS scores than the original DMs. LDMs also prove the quality on class-conditional generating and inpainting tasks.
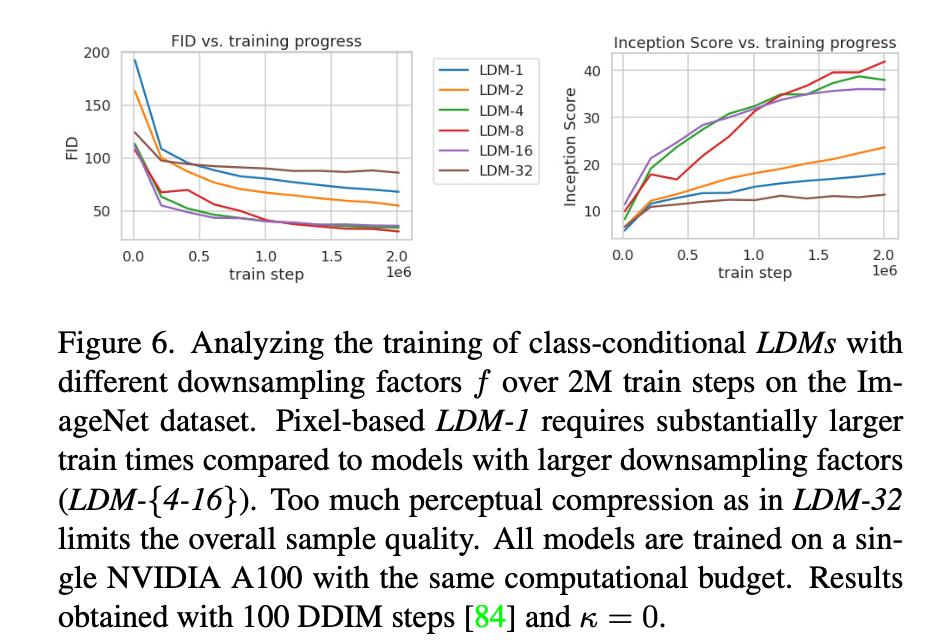
These results show that factor values of 4, 8, and 16 are suitible. 32 is too high to adequately represent the original information in the latent representation.
I assume that Pixel-based models do not focus on important feature.
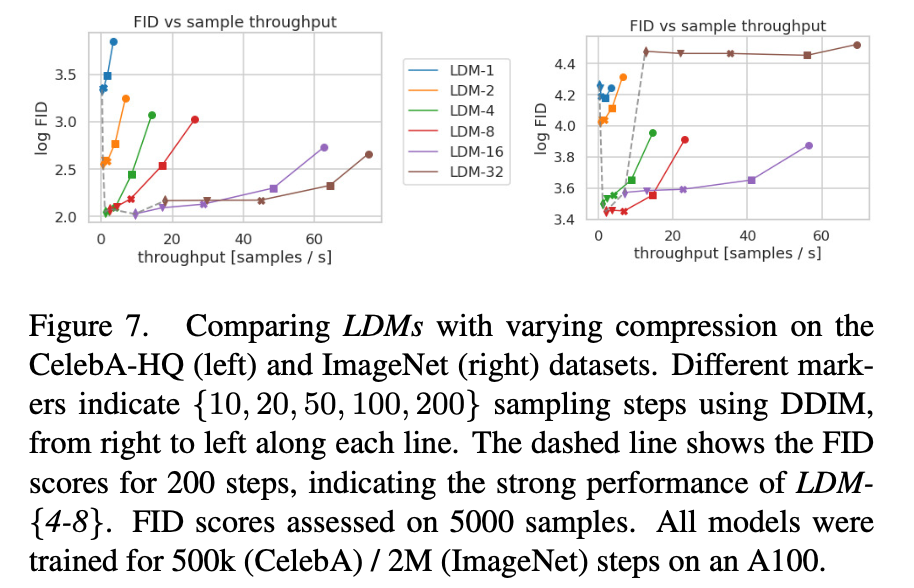 For CelebA-Hq, LDM-32 performs better than other models, but it performs poorly on ImageNet.
For CelebA-Hq, LDM-32 performs better than other models, but it performs poorly on ImageNet.
Q) Why does a higher factor lead to better performance for CelebA-HQ?
A) CelebA-HQ is a simple face image dataset. Therefore, it can be generated well with lower-dimensional latent representation.
LDM-1 consistently receives poor scores. I suppose that pixel-based model have to deal with too many features to generate high-quality images.
Generating images on each dataset.

Super-Resolution
 The SR3 model is a type of diffusion model for super-resolution. The figure shows that SR3 is able to capture fine structures.
The SR3 model is a type of diffusion model for super-resolution. The figure shows that SR3 is able to capture fine structures.
Inpainting
 As mentioned above, LDMs achieved SOTA FID scores on the inpainting task.
As mentioned above, LDMs achieved SOTA FID scores on the inpainting task.
human evaluation on SR and Inpainting
 LDM showed dominant results. 😮
LDM showed dominant results. 😮
Total organization of the architectures.
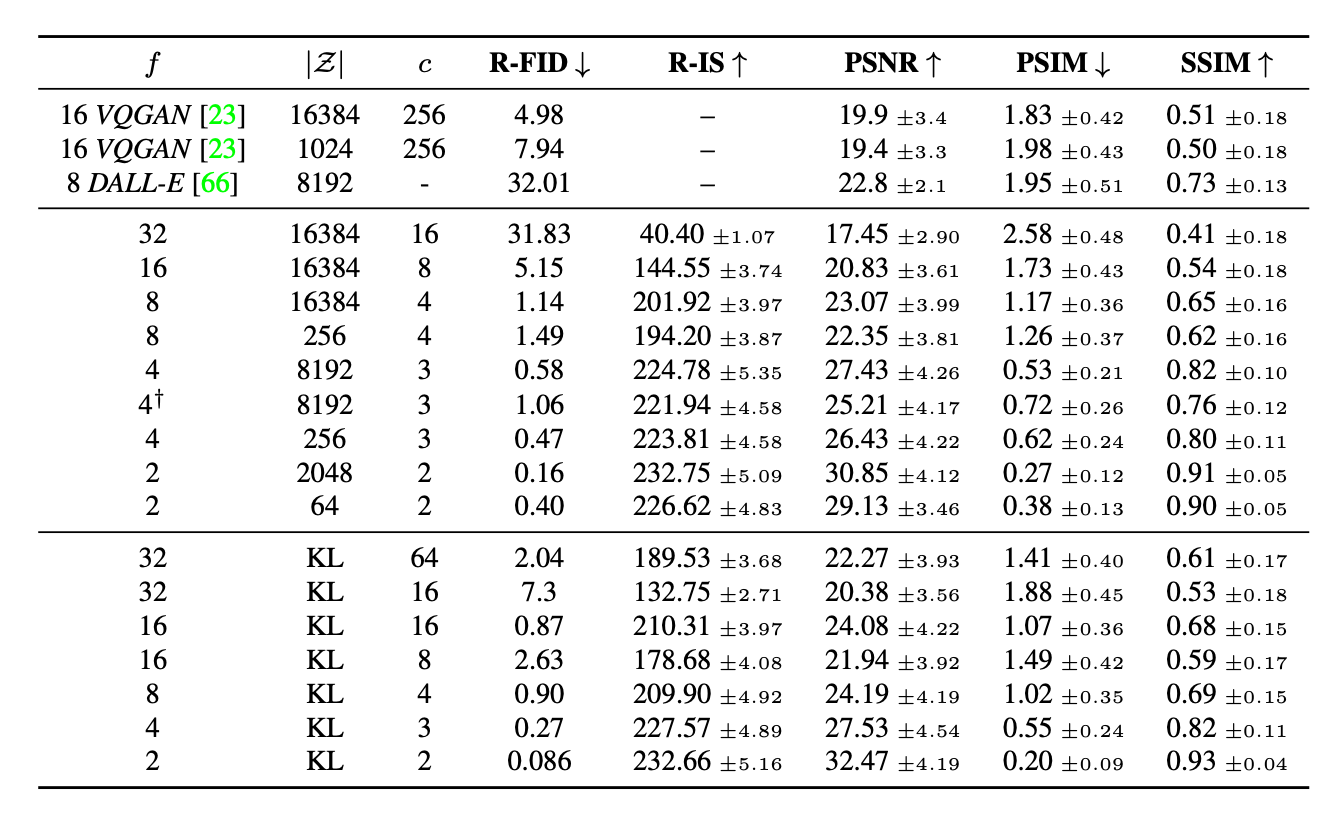 They trained on OpenImages, evaluated on ImageNet-Val.
We can see that there is a huge gap between f-32 and f-16 models.
They trained on OpenImages, evaluated on ImageNet-Val.
We can see that there is a huge gap between f-32 and f-16 models.
5. Conclusions
상당히 많은 실험들
- VAE, DDPM 등에서는 볼 수 없는 풍부한 task performance와 다양한 Baseline과의 비교
- DDPM을 기반으로 다양한 아키텍쳐를 제시한 만큼, 각각의 하이퍼파라미터에 따른 상세한 ablation study