Huggingface LLM Course - Chapter2 & Chapter3
Behind the pipeline:
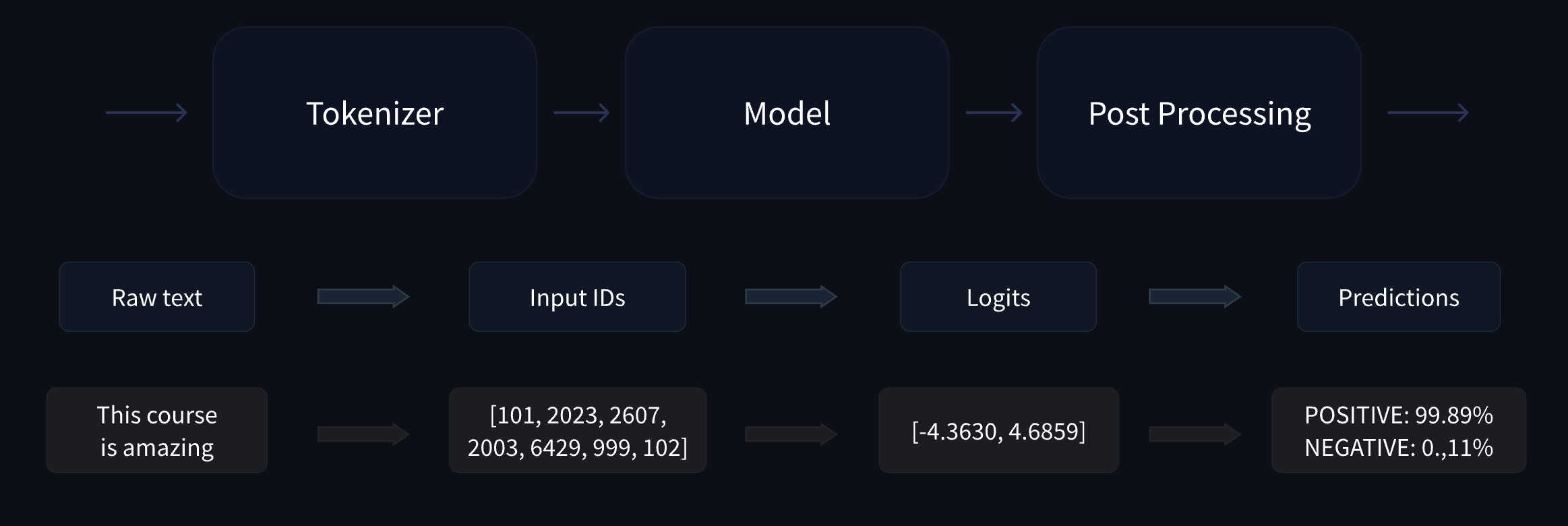
The vector output by the Transformer module is usually large. It generally has three dimensions:
- Batch size: The number of sequences processed at a time.
- Sequence length: The length of the numerical representation of the sequence.
- Hidden size: The vector dimension of each model input.
The hidden size can be very large. 768 is common for smaller models, and in larger models this can reach 3072 or more.
Model heads
The model heads take the high-dimensional vector of hidden states as input and project them onto a different dimension. They are usually composed of one or a few linear layers.
Model
from transformers import BertConfig, BertModel
config = BertConfig()
model = BertModel(config)This is to load the BERT's architecture with random values of weights. If I use it, it will output gibberish. It needs to be trained first but it takes a lot of time and resources. For preventing this, we can use a pre-trained model:
from transformers import BertModel
model = BertModel.from_pretrained("bert-base-cased")Tokenization
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
sequence = "Using a Transformer network is simple"
tokens = tokenizer.tokenize(sequence)
print(tokens)
>>> ['Using', 'a', 'transform', '##er', 'network', 'is', 'simple']From tokens to input IDs
ids = tokenizer.convert_tokens_to_ids(tokens)
print(ids)
>>>[7993, 170, 11303, 1200, 2443, 1110, 3014]Decoding
decoded_string = tokenizer.decode([7993, 170, 11303, 1200, 2443, 1110, 3014])
print(decoded_string)
>>> 'Using a Transformer network is simple'Send to Model
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
sequence = "I've been waiting for a HuggingFace course my whole life."
tokens = tokenizer.tokenize(sequence)
ids = tokenizer.convert_tokens_to_ids(tokens)
input_ids = torch.tensor(ids)
# This line will fail.
model(input_ids)
>>> IndexError: Dimension out of range (expected to be in range of [-1, 0], but got 1)Why did this fail?
Transformers models expect multiple sentences by default.
So, this is the right way to send it to the model:
input_ids = torch.tensor([ids])
model(input_ids)I will handle Datasets library later. Therefore, this post doesn't cover it detailedly.
Fine-tuning a model with the Trainer API:
from transformers import Trainer
trainer = Trainer(
model,
training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
)
trainer.train()Then Trainer will start the fine-tuning and report the training loss every 500 steps.
predictions = trainer.predict(tokenized_datasets["validation"])
print(predictions.predictions.shape, predictions.label_ids.shape)
>>> (408, 2) (408,)import numpy as np
import evaluate
preds = np.argmax(predictions.predictions, axis=-1)
metric = evaluate.load("glue", "mrpc")
metric.compute(predictions=preds, references=predictions.label_ids)
>>> {'accuracy': 0.8578431372549019, 'f1': 0.8996539792387542}But same reason as pipeline, I won't use this high-level APIs.
A full training
from datasets import load_dataset
from transformers import AutoTokenizer, DataCollatorWithPadding
raw_datasets = load_dataset("glue", "mrpc")
checkpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
def tokenize_function(example):
return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
tokenized_datasets = tokenized_datasets.remove_columns(["sentence1", "sentence2", "idx"])
tokenized_datasets = tokenized_datasets.rename_column("label", "labels") # model expects the argument to be named 'labels'
tokenized_datasets.set_format("torch") # therefore, they return PyTorch tensors instead of lists
tokenized_datasets["train"].column_names
>>> ["attention_mask", "input_ids", "labels", "token_type_ids"]define a dataloaders:
from torch.utils.data import DataLoader
train_dataloader = DataLoader(
tokenized_datasets["train"], shuffle=True, batch_size=8, collate_fn=data_collator
)
eval_dataloader = DataLoader(
tokenized_datasets["validation"], batch_size=8, collate_fn=data_collator
)To quickly check there is no mistake in the data processing:
for batch in train_dataloader:
break
{k: v.shape for k, v in batch.items()}
>>>{'attention_mask': torch.Size([8, 65]),
'input_ids': torch.Size([8, 65]),
'labels': torch.Size([8]),
'token_type_ids': torch.Size([8, 65])}After loading a pre-trained model:
outputs = model(**batch)
print(output.loss, outputs.logits.shape)
>>> tensor(0.5441, grad_fn=<NllLossBackward>) torch.Size([8, 2])Optimizer:
from transformers import AdamW
optimizer = AdamW(model.parameters(), lr=5e-5)Learning rate scheduler:
from transformers import get_scheduler
num_epochs = 3
num_training_steps = num_epochs * len(train_dataloader)
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps,
)Training roop:
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
model.to(device)
progress_bar = tqdm(range(num_training_steps))
model.train()
for epoch in range(num_epochs):
for batch in train_dataloader:
batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)The training flow is as follows:
- Calculate the loss
- Calculate the gradients during backpropagation
- Update the model parameters using the optimizer
- Tune the learning rate
- Initialize gradients to zero
With the Accelerate library, which enables more efficient and faster training performance, we need to make some minor revisions to the code.
accelerate = Accelerator()
...
train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(
train_dataloader, eval_dataloader, model, optimizer
)
...
model.train()
for epoch in range(num_epochs):
for batch in train_dataloader:
outputs = model(**batch)
loss = outputs.loss
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)accelerate.prepare() wraps these objects in the appropriate container to ensure your distributed training functions properly as intended.
Reference
https://huggingface.co/learn/llm-course/chapter2/1?fw=pt https://huggingface.co/learn/llm-course/chapter3/1?fw=pt