Huggingface LLM Course - Chapter5 (Datasets Library)
In chapter 5, docs handles datasets library. Key questions is following:
- What do you do when your dataset is not on the Hub?
- How can you slice and dice a dataset? (And what if you really need to use Pandas?)
- What do you do when your dataset is huge and will melt your laptop’s RAM?
- What the heck are “memory mapping” and Apache Arrow?
- How can you create your own dataset and push it to the Hub?
Common data formats:
| Data format | Loading script | Example |
|---|---|---|
| CSV & TSV | csv | load_dataset("csv", data_files="my_file.csv") |
| Text files | text | load_dataset("text", data_files="my_file.txt") |
| JSON & JSON Lines | json | load_dataset("json", data_files="my_file.jsonl") |
| Pickled DataFrames | pandas | load_dataset("pandas", data_files="my_dataframe.pkl") |
Load Datasets
from datasets import load_dataset
data_files = {"train": "SQuAD_it-train.json", "test": "SQuAD_it-test.json"}
squad_it_dataset = load_dataset("json", data_files=data_files, field="data")Or it is possible to put a raw string to data_files parameter.
Slice and dice
A good practice when doing any sort of data analysis is to grab a small random sample to get a quick feel for the type of data you’re working with. In 🤗 Datasets, we can create a random sample by chaining the Dataset.shuffle() and Dataset.select() functions together:
drug_sample = drug_dataset["train"].shuffle(seed=42).select(range(1000))
# Peek at the first few examples
drug_sample[:3]Shuffling and selecting small samples is quite a good practice!
drug_dataset.unique('drugName') is a function to find the number of unique drug names. We can pass any column names as a parameter.
def lowercase_condition(example):
return {"condition": example["condition"].lower()}
drug_dataset.map(lowercase_condition)
>>> AttributeError: 'NoneType' object has no attribute 'lower'We can infer that some of the entires in the
conditioncolumn areNone, which cannot be lowercased as they're not strings. Let's drop these rows using Dataset.filter(), which works in a similar way toDataset.map()and expects a function that receives a single example of the dataset.
drug_dataset = drug_dataset.filter(lambda x: x['condition'] is not None)filter and map method are similar to Javascript's. Filter removes falsey elements and only keeps truthy elements.
But what exactly is an element to which a method is applied?
For a single dataset, the method executes a task on each row. For a dataset dictionary, the method iterates through each split and performs a task on each row within that split.
def compute_review_length(example):
return {"review_length": len(example["review"].split())}
drug_dataset = drug_dataset.map(compute_review_length)
# Inspect the first training example
drug_dataset["train"][0]
>>> {'patient_id': 206461,
'drugName': 'Valsartan',
'condition': 'left ventricular dysfunction',
'review': '"It has no side effect, I take it in combination of Bystolic 5 Mg and Fish Oil"',
'rating': 9.0,
'date': 'May 20, 2012',
'usefulCount': 27,
'review_length': 17}drug_dataset = drug_dataset.filter(lambda x: x["review_length"] > 30)
print(drug_dataset.num_rows)
>>>{'train': 138514, 'test': 46108}The map() method’s superpowers
The Dataset.map() method takes a batched argument that, if set to True, causes it to send a batch of examples to the map function at once (the batch size is configurable but defaults to 1,000).
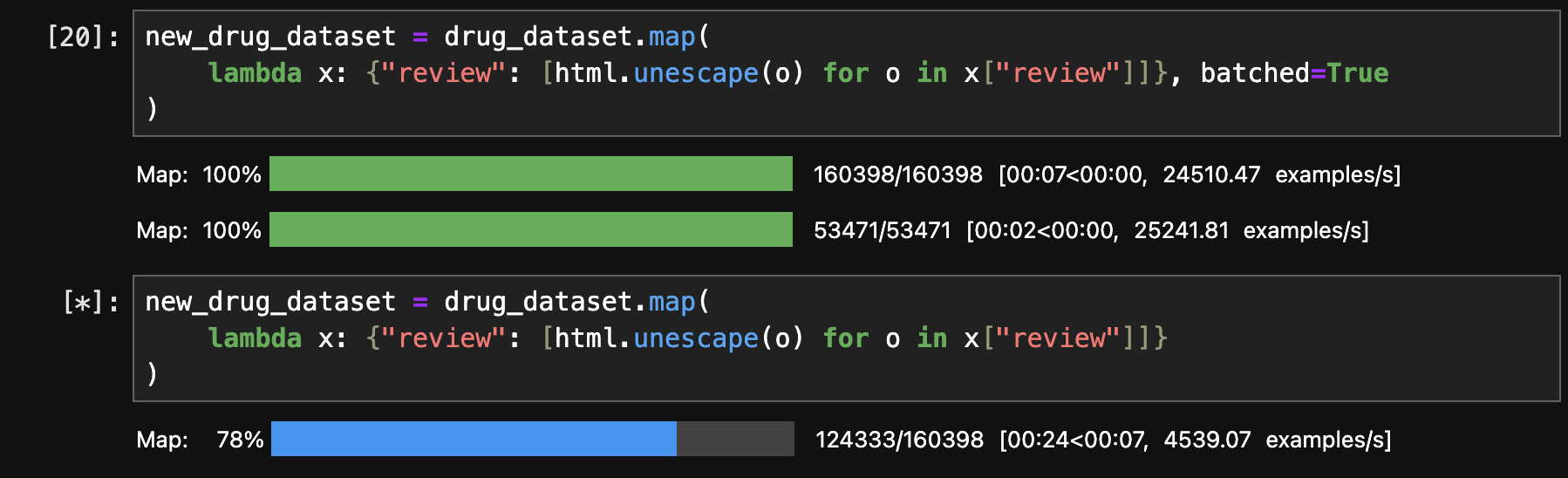
Wow, a false batch takes 5 times longer.
Tokenizer also can process a batch.
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
def tokenize_function(examples):
return tokenizer(examples["review"], truncation=True)Pandas
drug_dataset.set_format("pandas")Creating a validation set
🤗 Datasets provides a Dataset.train_test_split() function that is based on the famous functionality from scikit-learn. Let’s use it to split our training set into train and validation splits (we set the seed argument for reproducibility):
drug_dataset_clean = drug_dataset["train"].train_test_split(train_size=0.8, seed=42)
# Rename the default "test" split to "validation"
drug_dataset_clean["validation"] = drug_dataset_clean.pop("test")
# Add the "test" set to our `DatasetDict`
drug_dataset_clean["test"] = drug_dataset["test"]
drug_dataset_clean
>>> DatasetDict({
train: Dataset({
features: ['patient_id', 'drugName', 'condition', 'review', 'rating', 'date', 'usefulCount', 'review_length', 'review_clean'],
num_rows: 110811
})
validation: Dataset({
features: ['patient_id', 'drugName', 'condition', 'review', 'rating', 'date', 'usefulCount', 'review_length', 'review_clean'],
num_rows: 27703
})
test: Dataset({
features: ['patient_id', 'drugName', 'condition', 'review', 'rating', 'date', 'usefulCount', 'review_length', 'review_clean'],
num_rows: 46108
})
})pop('key') removes and returns the value associated with the specified key from the dictionary.
Saving a dataset
| Data format | Function |
|---|---|
| Arrow | Dataset.save_to_disk() |
| CSV | Dataset.to_csv() |
| JSON | Dataset.to_json() |
Dealing with huge data
the WebText corpus used to pretrain GPT-2 consists of over 8 million documents and 40 GB of text — loading this into your laptop’s RAM is likely to give it a heart attack! Fortunately, 🤗 Datasets has been designed to overcome these limitations. It frees you from memory management problems by treating datasets as memory-mapped files, and from hard drive limits by streaming the entries in a corpus.
So how does 🤗 Datasets solve this memory management problem? 🤗 Datasets treats each dataset as a memory-mapped file, which provides a mapping between RAM and filesystem storage that allows the library to access and operate on elements of the dataset without needing to fully load it into memory.
Semantic search with FAISS
There's a library called senetence-transformers that is dedicated to creating embeddings.
Following an example from the documentation, we're going to implement asymmetric semantic search, which is characterized by typically short queries (like a questions or keywords), while the target documents are longer paragraphs or passages containing the answer.
from transformers import AutoTokenizer, AutoModel
model_ckpt = "sentence-transformers/multi-qa-mpnet-base-dot-v1"
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
model = AutoModel.from_pretrained(model_ckpt)import torch
device = torch.device("cuda")
model.to(device)def cls_pooling(model_output):
return model_output.last_hidden_state[:, 0]
def get_embeddings(text_list):
encoded_input = tokenizer(
text_list, padding=True, truncation=True, return_tensors="pt"
)
encoded_input = {k: v.to(device) for k, v in encoded_input.items()}
model_output = model(**encoded_input)
return cls_pooling(model_output)embeddings_dataset = comments_dataset.map(
lambda x: {"embeddings": get_embeddings(x["text"]).detach().cpu().numpy()[0]}
)After embedding, let's use FAISS (short for Facebook AI Similarity Search). FAISS is a library that provides efficient algorithms to quickly search and cluster embedding vectors.
embeddings_dataset.add_faiss_index(column="embeddings")
question = "How can I load a dataset offline?"
question_embedding = get_embeddings([question]).cpu().detach().numpy()
question_embedding.shape
scores, samples = embeddings_dataset.get_nearest_examples(
"embeddings", question_embedding, k=5
)sorting by score:
import pandas as pd
samples_df = pd.DataFrame.from_dict(samples)
samples_df["scores"] = scores
samples_df.sort_values("scores", ascending=False, inplace=True)for _, row in samples_df.iterrows():
print(f"COMMENT: {row.comments}")
print(f"SCORE: {row.scores}")
print(f"TITLE: {row.title}")
print(f"URL: {row.html_url}")
print("=" * 50)
print()